What is AIOps? A practical guide to smarter IT operations



Modern IT stacks generate more telemetry than teams can review manually. As systems become more distributed, IT teams often lose time separating routine noise from events that need investigation.
Artificial intelligence for IT operations (AIOps) uses machine learning, analytics, and automation to make operational data easier to act on. It helps teams detect unusual behavior, investigate incidents, and prioritize which operational steps need attention first.
How does AIOps work?
One useful way to understand AIOps is to view it through four broad stages. First, the platform prepares operational data for analysis. Then it identifies patterns, turns findings into usable context, and applies automation where teams have defined safe response rules.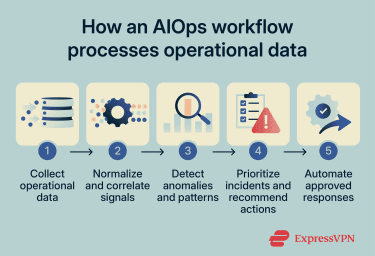
Data collection and integration
AIOps platforms ingest data from logs, metrics, traces, alerts, cloud telemetry, topology maps, application monitoring tools, and IT service management (ITSM) systems. These signals come from applications, containers, cloud services, networks, databases, and infrastructure platforms.
This data rarely arrives in a consistent format. Different tools use different schemas, timestamps, and naming conventions, which can make direct analysis difficult. Depending on the platform and its configuration, it may normalize data, align timestamps, reduce duplicate alerts, and tag related entities such as services, hosts, or applications.
Some platforms also link related signals using topology and dependency data. For example, database errors, infrastructure alerts, and application slowdowns may all relate to the same incident. This can provide a correlated operational view instead of a collection of isolated tool outputs.
AI-driven analysis and pattern detection
After organizing the data, AIOps platforms analyze it for anomalies, trends, and recurring patterns. Rules-based monitoring commonly uses fixed thresholds, such as triggering an alert when CPU usage reaches a set percentage. AIOps can supplement these rules with baselines, dynamic thresholds, correlation rules, or machine learning (ML) models to detect unusual system behavior.
This approach helps distinguish expected fluctuations from operational issues. A traffic spike during business hours may reflect normal activity, while the same spike at an unusual time could indicate a problem. Platforms can also identify patterns tied to deployments, infrastructure changes, service dependencies, or seasonal workloads.
Some AIOps platforms analyze multiple data streams together and link signals using topology and dependency data. For example, database errors, infrastructure alerts, and application slowdowns may all relate to the same incident. This broader analysis can reveal relationships that separate monitoring tools might miss.
Operational insights and recommendations
Once the platform detects meaningful patterns, it converts them into operational insights that teams can act on. Depending on the platform and data pipeline, these findings may be generated in real time, near real time, or through periodic analysis.
Instead of presenting operators with disconnected alerts, AIOps platforms prioritize incidents based on severity, affected services, dependency relationships, and potential business impact.
Through alert correlation and deduplication, some platforms group related alerts, suppress duplicates, and consolidate the remaining signals into a single incident object that includes linked services, recent changes, dependency data, and supporting evidence. This can help teams assess an incident’s wider impact. For example, a database failure may simultaneously disrupt application programming interfaces (APIs), applications, and downstream services.
Platforms can use this context to suggest possible root causes and next steps. However, correlation results, root-cause suggestions, and recommended actions should generally be treated as evidence for investigation rather than guaranteed conclusions. Incomplete telemetry, inaccurate dependency data, or poorly tuned models can cause related alerts to be missed, unrelated alerts to be grouped together, or root causes to be identified incorrectly.
Read more: Your comprehensive guide to cyber threat monitoring.
Automated actions and remediation
Many AIOps platforms can run predefined actions when telemetry matches approved conditions. These actions usually follow rules that teams configure in advance, especially for repeatable incidents with clear response paths.
Automated actions may include opening tickets, routing alerts, restarting services, scaling cloud resources, triggering scripts, launching runbooks, or, in some cases, initiating controlled rollback workflows. Teams can define rules, approval paths, and confidence thresholds before enabling these actions.
For high-impact actions, organizations should generally retain human review. A hybrid model can automate lower-risk tasks while requiring operators to approve major remediation steps.
Benefits of AIOps
AIOps can provide IT teams with a more structured approach to handling incidents, operational trends, and routine response work. It helps them turn scattered signals into clearer priorities, repeatable workflows, and better planning inputs.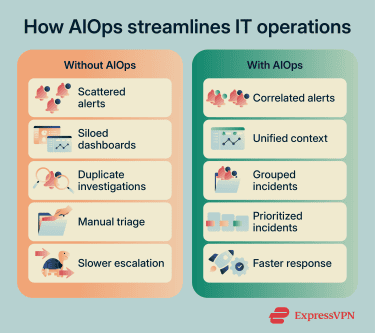
- Less alert noise: Teams can focus on higher-impact incidents rather than treating every notification as a separate problem requiring manual review.
- Faster incident triage: Engineers can move from alert review to investigation sooner because the platform provides a more organized view of the incident. This can reduce the time required to acknowledge and diagnose problems, thereby lowering mean time to resolve (MTTR).
- More consistent operational workflows: Teams can follow the same response logic during recurring incidents instead of relying on each operator’s memory or personal process.
- Better shared context: When the necessary topology and monitoring data are available, teams can view related services, dependencies, and user-facing impact in a single operational picture rather than relying on separate tool views.
- Stronger reliability planning: Long-term operational trends can show where teams need more capacity, stronger controls, or closer monitoring before recurring issues affect service health. When security telemetry is integrated, these insights may also support security posture.
- Lower operational overhead: IT teams spend less time on repetitive alert reviews, duplicate incident investigations, and routine operational tasks. This can help organizations manage larger environments without increasing operational workload at the same rate.
Drawbacks of AIOps
AIOps can improve IT operations, but its effectiveness depends heavily on complete and consistent telemetry, secure access controls, governance, and realistic rollout plans. Teams may get poor results if they connect tools without first addressing data gaps, access risks, or unclear response processes.
Data quality and integration challenges
AIOps platforms depend on operational telemetry that can be reliably mapped to the same services, resources, and time periods. If field names, timestamps, severity labels, or entity identifiers don't align, the platform may incorrectly connect signals or miss important relationships during an incident.
Data fragmentation creates another major problem. Many organizations split observability data across separate platforms for logs, infrastructure monitoring, application performance monitoring (APM), cloud telemetry, incident management, and security operations. Common gaps include:
- Missing or inconsistent tags across services and hosts.
- Duplicate alerts from overlapping monitoring tools.
- Incomplete telemetry from unsupported systems.
- Poorly configured alert thresholds that generate noise.
- Short data retention periods that limit historical analysis.
Data volume also matters. Collecting every log, event, or metric doesn’t automatically improve the quality of analysis. Large telemetry pipelines can increase storage costs, processing overhead, and alert noise if teams ingest low-value operational data without filtering or prioritization.
Data security and privacy risks
AIOps platforms often process sensitive operational and infrastructure data at scale. Logs, traces, access records, cloud telemetry, and incident reports can expose internal system architecture, user activity, service dependencies, and security events. Unauthorized users who gain access to this data may see sensitive operational details.
Integration can further increase the attack surface. AIOps platforms frequently integrate with monitoring systems, cloud environments, information technology service management (ITSM) platforms, automation tools, and security products, including extended detection and response (XDR) platforms. Weak credentials, excessive permissions, or insecure integrations can create operational and cybersecurity risks.
Organizations should pay close attention to:
- Role-based access controls for telemetry and incident data.
- API security and credential management.
- Data retention and deletion policies.
- Sensitive data masking inside logs and traces.
- Separation between production and non-production environments.
Automation can also introduce security concerns. If an AIOps platform can trigger operational changes automatically, a compromised workflow or automation account could be used to disrupt services or misuse privileged access. This risk is greater when automation accounts have excessive permissions or weak authentication controls.
Least-privilege access, approval controls, audit logging, and secure access paths can help reduce these risks in cloud-connected environments.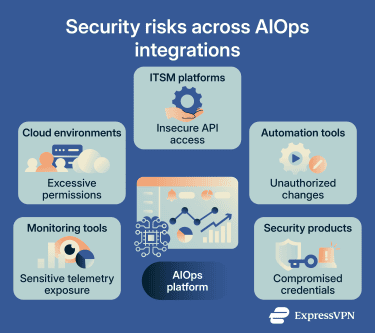
Risk of inaccurate insights
AIOps platforms can miss operational context when the available data is incomplete, stale, or poorly mapped. AIOps analysis may use historical telemetry, statistical models, ML baselines, topology data, and rule-based correlation. Because these inputs can become outdated as the environment changes, ongoing validation is necessary.
False positives remain a common problem in noisy environments. The platform may flag expected behavior as anomalous, especially after infrastructure changes, application updates, traffic spikes, or adjustments to monitoring rules. Teams may eventually ignore alerts if the system generates too many low-value incidents.
False negatives create a different risk. Missed anomalies can delay incident detection or leave contributing failures undiscovered. Separately, correlation logic may group unrelated events, while root-cause analysis may attribute an incident to the wrong component, particularly when several services fail simultaneously.
Complexity of implementation and adoption
AIOps deployments often require operational changes far beyond installing a new platform. Teams may need to redesign monitoring strategies, standardize telemetry, clean up alerting rules, retrain staff, and integrate multiple operational systems before the platform produces reliable results.
Workflow differences between teams can also slow adoption. Infrastructure, cloud, application, and security teams often use different escalation paths, monitoring standards, and incident processes, which makes automation and correlation harder to implement. An organization may also face challenges like:
- Integrating legacy systems with modern observability platforms.
- Standardizing telemetry and tagging across teams.
- Defining ownership for automated remediation workflows.
- Reducing alert noise before enabling automation.
- Building trust in machine-generated recommendations.
Teams increase operational risk when they enable broad automation before testing ownership, approval paths, and rollback behavior. Without these safeguards, AIOps automation can introduce unintended production changes.
Common AIOps use cases
AIOps is most commonly used in production operations where teams need to interpret activity across applications, infrastructure, cloud services, and incident workflows. It can also support pre-production testing, capacity planning, cloud migration, and continuous integration/continuous delivery (CI/CD) validation.
Anomaly detection in IT systems
Retail, media, and financial platforms often apply AIOps to telemetry streams where traffic volume changes sharply over time, across regions, or with user activity. The focus isn’t necessarily on a single metric but on the relationship among user demand, service health, and backend behavior.
For example, an e-commerce platform may use AIOps to track checkout latency, payment API failures, cache miss rates, and sudden spikes in database query volume during seasonal traffic events. A streaming platform may monitor abnormal buffering rates, changes in content delivery network (CDN) traffic, and regional service degradation across large volumes of active sessions.
Root cause analysis
Modern applications depend on interconnected services, APIs, databases, cloud workloads, and network infrastructure. When failures spread across several systems, teams may struggle to identify the underlying cause and distinguish it from downstream symptoms.
For example, a failed Kubernetes node may lead to pod termination and replacement, application latency, lost database connections, and downstream API timeouts. An AIOps platform can correlate these signals within a single incident timeline, helping operators investigate how the infrastructure failure relates to changes in application behavior.
Predictive analytics and early incident detection
Some organizations use AIOps to identify operational patterns that repeatedly appear before infrastructure failures or service degradation. These systems analyze historical telemetry to detect recurring operational conditions tied to outages, instability, or resource exhaustion.
For example, a cloud provider may monitor storage growth and capacity forecasts before workloads hit allocation limits, while a financial platform may track transaction queue growth and increasing database latency before user-facing services slow down during peak activity.
Process automation
IT operations teams frequently repeat the same actions during incidents, maintenance events, and escalation workflows. Organizations often use AIOps to automate operational tasks that follow predefined rules and require minimal decision-making.
For example, an operations team may configure an AIOps workflow to respond to a known crash loop by creating an incident record, attaching container logs, paging the service owner, and linking the runbook that engineers already use for that failure pattern.
Cloud infrastructure management
Cloud infrastructure changes continuously as workloads scale, containers restart, updates are deployed, and applications span on-premises infrastructure, Infrastructure-as-a-Service (IaaS), Platform-as-a-Service (PaaS), and other managed cloud platforms.
Organizations can use AIOps to track operational relationships across these dynamic systems. This can include monitoring the cloud infrastructure supporting large Internet of Things (IoT) cloud deployments, where backend systems process and route high volumes of operational device telemetry.
For example, a multi-cloud deployment may use AIOps to monitor autoscaling behavior, container scheduling failures, unhealthy load balancer targets, cloud network bottlenecks, and regional failover events across Kubernetes clusters and cloud providers.
Application performance monitoring
AIOps can augment application performance monitoring (APM) by analyzing and correlating metrics, logs, traces, infrastructure events, and dependency data from distributed applications. In these architectures, a single transaction may pass through APIs, databases, microservices, authentication systems, message queues, and external services before completing.
For example, an online banking platform may use distributed tracing to follow slow account transfers across frontend APIs, backend transaction services, fraud-detection systems, and databases. AIOps can correlate those traces with infrastructure and application telemetry to help identify likely bottlenecks.
A Software-as-a-Service (SaaS) provider may similarly use AIOps to assess how third-party API latency relates to problems with dashboards, authentication flows, or background synchronization jobs.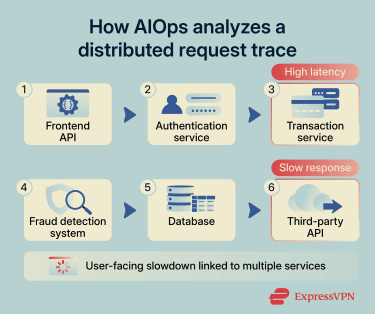
Key stages of AIOps adoption
A practical AIOps rollout can be organized into stages. Each stage answers a different question: what problem the platform should address, which data it needs, how teams will use its outputs, and when the rollout can expand safely.
Assessment and planning
Organizations can begin by choosing one bounded operational workflow for the first rollout. A suitable first workflow has clear inputs, defined owners, limited production risk, and measurable handoffs between tools or teams. This narrow scope helps teams evaluate platform outputs and measure value before expanding to more systems.
Teams also need clear operational goals before evaluating platforms or automation workflows. During this stage, organizations can define:
- The first workflow the rollout will target.
- The teams and systems the rollout will affect.
- The actions that will require human approval.
- The metrics that will define success.
These decisions shape the rest of the deployment. An organization focused on incident correlation may choose a different rollout strategy from one prioritizing cloud infrastructure visibility or automated remediation.
Data preparation and tool selection
AIOps platforms depend heavily on the quality of telemetry, so teams may need to prepare operational data before expanding deployment. This process can begin with a telemetry inventory. Teams map which logs, metrics, traces, alerts, incident records, and dependency data support the use case, then identify an owner for each source before connecting it to the platform.
Organizations also need to evaluate whether the platform works with their existing operational systems. Important considerations include:
- Support for existing observability and monitoring tools.
- Integration with cloud platforms and ITSM systems.
- Compatibility with automation workflows and APIs.
- Support for multi-cloud or hybrid-environment telemetry.
- Access controls, audit logging, and governance features.
Teams can then run a limited ingestion test before expanding coverage. This helps verify that the platform receives the right fields and timestamps and can map the relevant services for the target workflow.
Implementation and workflow integration
During implementation, teams integrate the platform into existing operational processes and communication channels. At this stage, teams also decide where AIOps outputs should be delivered or used during daily operations, such as:
- Incident records for the investigation context.
- On-call queues for ownership and escalation.
- Dashboards for service-level review.
- Runbooks or automation tools for approved response steps.
- Team channels for operational updates.
Organizations also define approval paths, escalation rules, rollback procedures, and automation boundaries before enabling higher-risk operational actions.
Continuous optimization and scaling
AIOps deployments need an ongoing review cycle. Teams should compare platform outputs with real-world incident records, operator feedback, runbook results, and integration logs to identify areas needing tuning.
Once the platform performs reliably in the first workflow, teams can expand it into additional services, teams, or response processes. Higher-risk automated remediation should come later, after teams have validated the platform’s outputs, approval paths, and rollback controls.
AIOps compared to related concepts
AIOps often overlaps with modern IT practices, but it doesn’t replace them. It supports IT operations analysis and response, while development operations (DevOps), machine learning operations (MLOps), site reliability engineering (SRE), and agentic AI focus on different parts of software delivery, model operations, reliability, or autonomous task execution.
AIOps vs. DevOps
DevOps is a software delivery and operations practice that brings development and operations teams closer together. It focuses on faster releases, stronger collaboration, CI/CD, infrastructure-as-code (IaC), and shared responsibility for production systems.
AIOps can complement DevOps as an operations intelligence layer. DevOps shapes how teams build, deploy, and operate software; AIOps analyzes production telemetry and service-management data to help teams interpret system behavior, detect operational risks, and assess the impact of infrastructure or application changes.
For example, a DevOps team may use CI/CD pipelines to release a new service, while AIOps helps interpret its operational behavior after deployment.
Also read: What is DevSecOps? Securing software development from the start.
AIOps vs. MLOps
MLOps focuses on the ML lifecycle. It covers how teams build, train, deploy, monitor, govern, and update ML models in production. Its main concerns are model reliability, version control, data pipelines, reproducibility, drift detection, and responsible deployment.
AIOps, by contrast, applies ML and other analytical techniques to IT operations without necessarily managing the models behind them.
The practices can intersect when an organization develops custom models for AIOps use cases. In that situation, an MLOps pipeline may develop, deploy, and update the models that AIOps applies to operational workflows. However, many AIOps platforms use embedded or vendor-managed models and do not require a separate MLOps pipeline.
AIOps vs. SRE
SRE is an engineering discipline for running reliable systems at scale. SRE teams often work with service-level objectives (SLOs), error budgets, incident response, capacity planning, automation, and reliability-focused software engineering.
AIOps can support SRE work, but it doesn’t define a reliability strategy. It can supply production evidence, but SRE teams and service owners still define reliability targets, decide acceptable risk, and choose the engineering practices that keep services within those limits.
AIOps vs. agentic AI
Agentic AI refers to AI systems that can plan and carry out multi-step tasks with greater autonomy. These systems may use tools, make decisions across steps, and adapt their actions based on changing context.
AIOps has a narrower domain. It focuses on IT operations data, incidents, observability, and remediation workflows. Agentic capabilities can appear in AIOps-style workflows, such as systems that investigate incidents across tools or draft remediation plans.
In production environments, agentic capabilities within AIOps should follow existing change-control and incident-management rules. Access restrictions, activity logging, approval gates, and rollback controls should reflect the risk of the actions an agent can perform.
Frequently asked questions
Does AIOps replace IT operations teams?
What data is needed for AIOps to work well?
Is AIOps only useful for large enterprises?
How long does it take to implement AIOps?
What skills are needed to work with AIOps?
How do you measure the success of AIOps?
What are common mistakes when adopting artificial intelligence for IT operations (AIOps)?
Can AIOps improve cybersecurity operations?
Take the first step to protect yourself online. Try ExpressVPN risk-free.
Get ExpressVPN